Как часто вы слышите от заказчиков, что они пришлют данные в Excel или просят вас сделать импорт или выгрузку в Excel-совместимом формате? Я уверен, что в большинстве сфер Excel — один из самых популярных, мощных и в то же время простых и удобных инструментов. Но самым проблемным моментом всегда остается интеграция таких данных с различными автоматизированными системами. Нашу команду попросили рассмотреть возможность проведения расчётов данных, используя настройки из пользовательского Excel-файла.
Если вам необходимо выбрать производительную библиотеку для работы с Excel-файлами или вы ищете решение для расчёта сложных финансовых (и не только) данных с удобным инструментом управления и визуализации формул из коробки, добро пожаловать.
Изучая требования нового проекта в компании, мы обнаружили один очень интересный пункт: «Разработанное решение должно уметь рассчитывать стоимость продукта (а именно — балкона) при изменении конфигурации и мгновенно отображать новую стоимость на интерфейсе. Необходимо предоставить возможность загрузки Excel-файла со всеми функциями расчёта и прайс-листами компонентов». Клиенту требовалось разработать портал для проектирования конфигурации балконов в зависимости от размеров, форм, видов остекления и используемых материалов, типов креплений, а также многих других сопутствующих параметров, которые применяются для расчёта точной стоимости производства и показателей надёжности.
Формализуем входные требования, чтобы было проще понимать, в каком контексте нужно было решить задачу:
- Быстрый расчёт цены на интерфейсе при изменениях параметров балкона;
- Быстрый расчёт проектных данных, включающий множество разных конфигураций балконов и индивидуальных предложений, поставляемых отдельным файлом расчетов;
- В перспективе — развитие функциональности с применением различных ресурсозатратных операций (задачи оптимизации параметров и т.д.)
- Всё это — на удалённом сервере с выводом через API, т.к. все формулы являются интеллектуальной собственностью заказчика и не должны быть видны третьим лицам;
- Поток входных данных с пиковыми нагрузками: пользователь может часто и быстро менять параметры, чтобы подобрать конфигурацию продукта по своим требованиям.
Звучит очень необычно и сверхзаманчиво, приступим!
Готовые решения и подготовка данных
Любое исследование для решения сложных задач начинается с сёрфинга по StackOverflow, GitHub и множеству форумов в поисках готовых решений.
Было отобрано несколько готовых решений, которые поддерживали чтение данных из Excel-файлов, а также умели производить расчёты на основе формул, указанных внутри библиотеки. Среди данных библиотек присутствуют как полностью бесплатные решения, так и коммерческие разработки.
| Библиотека | Ссылка | Документация | Лицензия |
|---|---|---|---|
| EPPlus 4 | Link | Link | GNU Library General Public License |
| EPPlus 5 | Link | Link | Polyform Noncommercial License 1.0.0 (Link) |
| NPOI | Link | Link | Apache License 2.0 |
| Spire | Link | Link | Link |
| Excel Interop (Microsoft.Office.Interop.Excel) | n/a | Link | Требует предустановленного Excel со всеми вытекающими последствиями лицензирования |
Следующим шагом является написание нагрузочных тестов и измерение времени работы каждой библиотеки. Для этого необходимо подготовить тестовые данные. Создаём новый Excel-файл, определяем 10 ячеек для входных параметров и одну (запомните этот момент) формулу для получения результата, которая использует все входные параметры. В формуле стараемся использовать все возможные математические функции различной вычислительной сложности и скомбинировать их хитрым способом.
Т.к. речь идёт ещё и о деньгах (стоимость продукта), то важно посмотреть и на точность полученных результатов. За эталон в данном случае будем брать результирующие значения, которые были получены с помощью Excel Interop, т.к. данные, полученные этим способом, вычислены через ядро Excel и равны значениям, которые заказчики видят при разработке формул и ручном расчете стоимости.
В качестве эталонного времени выполнения мы будем использовать нативный код, вручную написанный на чистом C#, чтобы отображать такую же формулу, записанную в Excel.
Переведённая исходная формула для тестирования:
public double Execute(double[] p)
{
return Math.Pow(p[0] * p[8] / p[4] * Math.Sin(p[5]) * Math.Cos(p[2]) +
Math.Abs(p[1] - (p[2] + p[3] + p[4] + p[5] + p[6] + p[7] + p[8]))
* Math.Sqrt(p[0] * p[0] + p[1] * p[1]) / 2.0 * Math.PI, p[9]);
}
Формируем поток случайных входных данных для N итераций (в данном случае мы используем 10000 векторов).
Запускаем расчёты для каждого вектора входных параметров на всём потоке, получаем результаты и замеряем время инициализации библиотеки и общего расчёта.
Для сравнения точности полученных результатов мы используем два показателя — среднеквадратическое отклонение и процент совпавших значений с определённым шагом точности epsilon. При случайном формировании списка входных значений с плавающей точкой после запятой, необходимо определить точность входных параметров — это позволит получить корректные результаты. В ином случае, случайные числа могут иметь большую разность порядков — это может сильно отразиться на точности результатов и повлиять на оценку погрешности результата.
Т.к. изначально мы предполагаем, что требуется оперировать константными значениями стоимости материалов, а также некоторыми константами из разных областей знаний, мы можем принять, что все входные параметры будут иметь значения с точностью до 3 знаков после запятой. В идеальном варианте требуется задать допустимую область значений для каждого из параметров и использовать для генерации случайных значений только их, но т.к. формула для тестирования составлялась случайным образом без какого-либо математического и физического обоснования, то рассчитать такую область значений для всех 10 параметров не представляется возможным за разумный период времени. Поэтому в расчётах иногда можно получить ошибку вычислений. Исключим такие входные векторы данных уже в момент вычислений для показателей точности, но будем подсчитывать такие ошибки в качестве отдельной характеристики.
Архитектура тестов
Для каждой отдельной библиотеки был создан собственный класс, реализующий интерфейс ITestExecutor и включающий в себя 3 метода — SetUp, Execute и TearDown.
public interface ITestExecutor
{
// Инициализация библиотеки и других дополнительных данных
void SetUp();
// Выполнение полезной нагрузки, вычисление формулы на основе входного вектора данных и возвращение результата расчета
double Execute(double[] p);
// Завершение работы с библиотекой, освобождение памяти и хендлеров при необходимости
void TearDown();
}
Методы SetUp и TearDown используются единожды в процессе тестирования библиотеки и не учитываются при замере времени расчётов на всём наборе входных данных.
В итоге алгоритм тестирования свёлся к следующему:
- Подготовка данных (формируем поток входных векторов заданной точности);
- Выделение памяти под результирующие данные (массив результатов на каждую библиотеку, массив с количеством ошибок);
- Инициализация библиотек;
- Получение результатов расчётов для каждой из библиотек с сохранением полученного результата в заранее заготовленный массив и записью времени исполнения;
- Завершение работы с кодом библиотек;
- Анализ полученных данных:
Графическое отображение данного алгоритма представлено ниже.
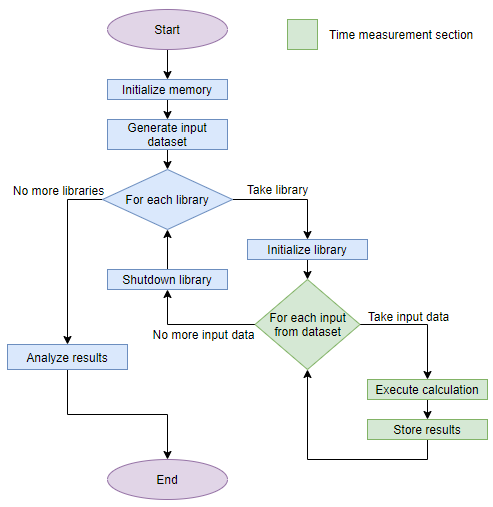
Результаты первой итерации
| Показатель | Native | EPPlus 4 & EPPlus 5 |
NPOI | Spire | Excel Interop |
| Время инициализации (мс) | 0 | 257 | 266 | 632 | 1653 |
| Ср. время на 1 проход (мс) | 0,0002 | 0,4086 | 0,6847 | 6,9782 | 38,8423 |
| Ср.кв. отклонение | 0,000394 | 0,000395 | 0,000237 | 0,000631 | n/a |
| Точность | 99,99% | 99,92% | 99,97% | 99,84% | n/a |
| Ошибки | 0,0% | 1,94% | 1,94% | 1,52% | 1,94% |
Почему результаты EPPlus 5 и EPPlus 4 объединены?
Первая итерация тестов показала неплохой результат, в котором сразу же стали видны лидеры среди библиотек. Как видно из приведённых данных, абсолютным лидером в данной ситуации является библиотека EPPlus.
Результаты не впечатляющие по сравнению с нативным кодом, но жить можно.
На этом можно было бы и остановиться, но после общения с заказчиками закрались первые сомнения: результаты получились слишком хорошие.

Особенности работы с библиотекой Spire
В ходе работы с библиотекой Spire было обнаружено, что она очень часто возвращает некорректные значения и постоянно выдаёт ошибки вида InvalidCastException. В ходе детального расследования было выявлено, что при первом неудачном расчёте встроенная система вычислений формул Excel-файла не имеет механизмов восстановления, и поэтому любые последующие вычисления, даже на корректном векторе входных данных, приводили к такой же ошибке. Для решения этой проблемы нам пришлось в таких ситуациях заново инициализировать объекты библиотеки для работы с файлами в блоке try...catch. После этого исправления данные стали обрабатываться корректно, и число ошибок в библиотеке выровнялось до общего уровня.
Грабли первой итерации тестов
Выше я просил обратить ваше внимание на один момент, который сыграл важную роль в получении результатов. Мы подозревали, что формулы, используемые в реальном Excel-файле заказчика будут далеко не примитивными, с множеством зависимостей внутри, но не подозревали, что это может сильно отразиться на показателях. Тем не менее, изначально, при составлении тестовых данных, я это не предусмотрел, а данные от заказчика (хотя бы информация о том, что в итоговом файле используется не меньше 120 входных параметров) намекнули, что необходимо задуматься и добавить формулы с зависимостями между ячейками.
Приступаем к подготовке новых данных для следующей итерации тестирования. Остановимся на 10 входных параметрах и добавим дополнительно 4 новые формулы с зависимостью только от параметров и 1 агрегирующую формулу, которая базируется на этих четырёх ячейках с формулами и будет также опираться на значения входных данных.
Новая формула, которая будет использоваться для последующих тестов:
public double Execute(double[] p)
{
var price1 = Math.Pow(p[0] * p[8] / p[4] * Math.Sin(p[5]) * Math.Cos(p[2]) +
Math.Abs(p[1] - (p[2] + p[3] + p[4] + p[5] + p[6] + p[7] + p[8]))
* Math.Sqrt(p[0] * p[0] + p[1] * p[1]) / 2.0 * Math.PI, p[9]);
var price2 = p[4] * p[5] * p[2] / Math.Max(1, Math.Abs(p[7]));
var price3 = Math.Abs(p[7] - p[3]) * p[2];
var price4 = Math.Sqrt(Math.Abs(p[1] * p[2] + p[3] * p[4] + p[5] * p[6]) + 1.0);
var price5 = p[0] * Math.Cos(p[1]) + p[2] * Math.Sin(p[1]);
var sum = p[0] + p[1] + p[2] + p[3] + p[4] + p[5] + p[6] + p[7] + p[8] + p[9];
var price6 = sum / Math.Max(1, Math.Abs((p[0] + p[1] + p[2] + p[3]) / 4.0))
+ sum / Math.Max(1, Math.Abs((p[4] + p[5] + p[6] + p[7] + p[8] + p[9]) / 6.0));
var pricingAverage = (price1 + price2 + price3 + price4 + price5 + price6) / 6.0;
return pricingAverage / Math.Max(1, Math.Abs(price1 + price2 + price3 + price4 + price5 + price6));
}
Как можно заметить, результирующая формула получилась значительно сложнее, что естественным образом сказалось и на результатах — не в лучшую сторону. Таблица с результатами представлена ниже:
| Показатель | Native | EPPlus 4 EPPlus 5 |
NPOI | Spire | Excel Interop |
| Время инициализации (мс) | 0 | 241 | 368 | 722 | 1640 |
| Ср. время на 1 проход (мс) | 0,0004 | 0,9174 (+124%) | 1,8996 (+177%) | 7,7647 (+11%) | 50,7194 (+30%) |
| Ср.кв. отклонение | 0,035884 | 0,000000 | 0,000000 | 0,000000 | n/a |
| Точность | 98,79% | 100,00% | 100,00% | 100,00% | n/a |
| Ошибки | 0,0% | 0,3% | 0,3% | 0,28% | 0,3% |
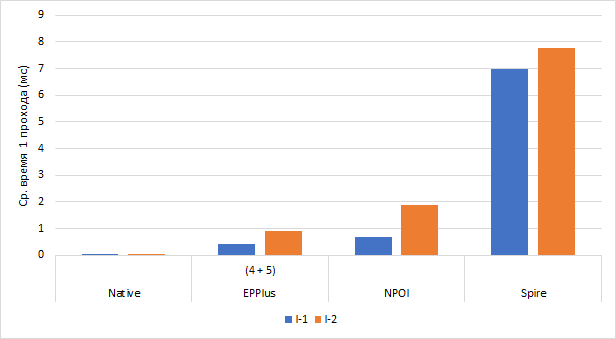
Примечание: Т.к. Excel Interop имеет слишком большие значения, их пришлось исключить из диаграммы.
Как видно из полученных результатов, ситуация стала совершенно непригодной для использования в продакшене. Немного грустим, запасаемся кофе и ныряем с головой ещё глубже в исследование — прямиком в кодогенерацию.

Кодогенерация
Если вы вдруг никогда не сталкивались с похожей задачей, то проведём краткий экскурс.
Кодогенерация — способ решения задачи с помощью динамического формирования исходного кода на основе входных данных с последующей компиляцией и исполнением. Существует как статичная кодогенерация, которая выполняется во время билда проекта (в качестве примера могу привести T4MVC, который создаёт на основе шаблонов и метаданных кода новый код, которые можно использовать при написании основного кода приложения), и динамическая — которая выполняется во время рантайма.
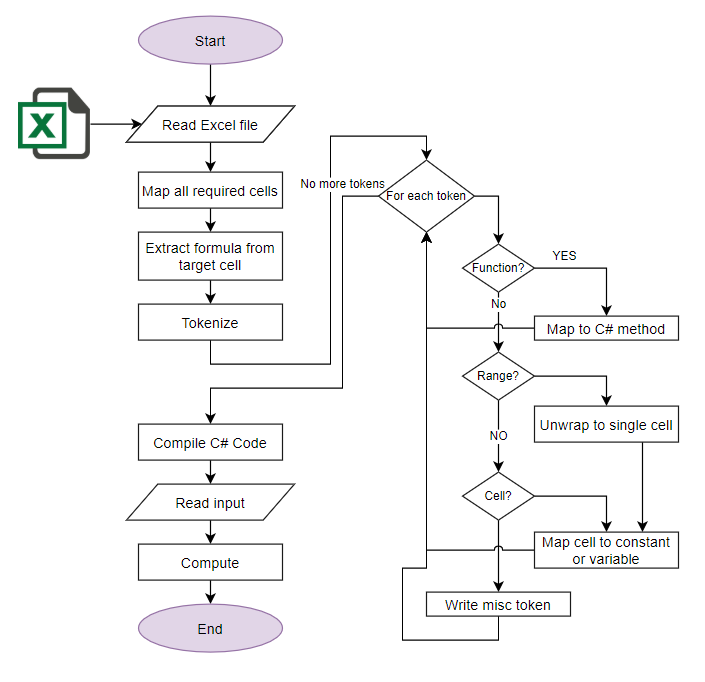
Наша задача состоит в том, чтобы на основе исходных данных (формулы из Excel) сформировать новую функцию, которая получает результат на основе вектора входных значений.
Для этого необходимо:
- Прочитать формулу из файла;
- Собрать все зависимости;
- Транслировать полученные формулы в аналогичный код на C#;
- Скомпилировать динамическую сборку с новой функцией;
- Подключить её к текущему процессу и пробросить ссылку на функцию для дальнейшего использования;
- Использовать полученную функцию для расчёта результатов.
Для чтения формул подходят все представленные библиотеки, однако самый удобный интерфейс для такого функционала оказался у библиотеки EPPlus. Немного порывшись в исходниках этой библиотеки, я обнаружил публичные классы для формирования списка токенов и дальнейшего его преобразования в дерево выражений. Бинго, подумал я! Готовое дерево выражений из коробки — это идеальный вариант, достаточно лишь пройтись по нему и сформировать наш код на C#.
Но большой подвох ожидал меня, когда я начал изучать узлы полученного дерева выражений. Некоторые узлы, в частности вызов функций Excel, инкапсулировали в себе информацию по используемой функции и её входным параметрам и не предоставляли никакого открытого доступа к этим данным. Поэтому работу с готовым деревом выражений пришлось отложить.
Идём на уровень ниже и пробуем работу со списком токенов. Здесь всё достаточно просто: у нас есть токены, которые имеют тип и значение. Т.к. нам дана функция и нам необходимо сформировать функцию, то мы можем вместо построения дерева преобразовать токены в эквивалент на C#. Главное в таком подходе — это организовать совместимые функции. Большинство математических функций уже были совместимы — такие как вычисление косинуса, синуса, получение корня и возведение в степень. Но функции агрегации — такие как максимальное значение, минимальное, сумма — требовалось доработать. Основное отличие в том, что в Excel данные функции работают с диапазоном значений. Для простоты прототипа мы сделаем функции, которые на вход принимают список параметров, предварительно разворачивая диапазон значений в линейный список. Таким образом мы получим корректное и совместимое преобразование из Excel-синтаксиса в C#-синтаксис.
Ниже представлен основной код преобразования списка токенов Excel-формулы в валидный C#-код.
private string TransformToSharpCode(string formula, ParsingContext parsingContext)
{
// Initialize basic compile components, e.g. lexer
var lexer = new Lexer(parsingContext.Configuration.FunctionRepository, parsingContext.NameValueProvider);
// List of dependency variables that can be filled during formula transformation
var variables = new Dictionary<string, string>();
using (var scope = parsingContext.Scopes.NewScope(RangeAddress.Empty))
{
// Take resulting code line
var compiledResultCode = TransformToSharpCode(formula, parsingContext, scope, lexer, variables);
var output = new StringBuilder();
// Define dependency variables in reverse order.
foreach (var variableDefinition in variables.Reverse())
{
output.AppendLine($"var {variableDefinition.Key} = {variableDefinition.Value};");
}
// Take the result
output.AppendLine($"return {compiledResultCode};");
return output.ToString();
}
}
private string TransformToSharpCode(ICollection<Token> tokens, ParsingContext parsingContext, ParsingScope scope, ILexer lexer, Dictionary<string, string> variables)
{
var output = new StringBuilder();
foreach (Token token in tokens)
{
switch (token.TokenType)
{
case TokenType.Function:
output.Append(BuildFunctionName(token.Value));
break;
case TokenType.OpeningParenthesis:
output.Append("(");
break;
case TokenType.ClosingParenthesis:
output.Append(")");
break;
case TokenType.Comma:
output.Append(", ");
break;
case TokenType.ExcelAddress:
var address = token.Value;
output.Append(TransformAddressToSharpCode(address, parsingContext, scope, lexer, variables));
break;
case TokenType.Decimal:
case TokenType.Integer:
case TokenType.Boolean:
output.Append(token.Value);
break;
case TokenType.Operator:
output.Append(token.Value);
break;
}
}
return output.ToString();
}
Следующим нюансом при конвертации было использование констант Excel — они представляют собой функции, поэтому в C# их также придется обернуть в функцию.
Осталось решить только один вопрос: преобразование ссылок на ячейку в параметр. В том случае, когда токен содержит информацию о ячейке, мы в первую очередь определяем, что именно хранится в этой ячейке. Если это формула — разворачиваем её рекурсивно. Если константа — заменяем на ссылку C#-аналога, вида p[row, column], где p может быть как двумерным массивом, так и классом с индексным доступом для корректного маппинга данных. С диапазоном ячеек мы делаем то же самое, только предварительно разворачиваем диапазон в индивидуальные ячейки и обрабатываем их отдельно. Таким образом, мы покрываем основной функционал при трансляции Excel-функции.
Ниже представлен код преобразования ссылки на ячейку Excel-таблицы в валидный C#-код:
private string TransformAddressToSharpCode(string excelAddress, ParsingContext parsingContext, ParsingScope scope, ILexer lexer, Dictionary<string, string> variables)
{
// Try to parse excel range of addresses
// Currently, reference to another worksheet in address string is not supported
var rangeParts = excelAddress.Split(':');
if (rangeParts.Length == 1)
{
// Unpack single excel address
return UnpackExcelAddress(excelAddress, parsingContext, scope, lexer, variables);
}
// Parse excel range address
ParseAddressToIndexes(rangeParts[0], out int startRowIndex, out int startColumnIndex);
ParseAddressToIndexes(rangeParts[1], out int endRowIndex, out int endColumnIndex);
var rowDelta = endRowIndex - startRowIndex;
var columnDelta = endColumnIndex - startColumnIndex;
var allAccessors = new List<string>(Math.Abs(rowDelta * columnDelta));
// TODO This part of code doesn't support reverse-ordered range address
for (var rowIndex = startRowIndex; rowIndex <= endRowIndex; rowIndex++)
{
for (var columnIndex = startColumnIndex; columnIndex <= endColumnIndex; columnIndex++)
{
// Unpack single excel address
allAccessors.Add(UnpackExcelAddress(rowIndex, columnIndex, parsingContext, scope, lexer, variables));
}
}
return string.Join(", ", allAccessors);
}
private string UnpackExcelAddress(string excelAddress, ParsingContext parsingContext, ParsingScope scope, ILexer lexer, Dictionary<string, string> variables)
{
ParseAddressToIndexes(excelAddress, out int rowIndex, out int columnIndex);
return UnpackExcelAddress(rowIndex, columnIndex, parsingContext, scope, lexer, variables);
}
private string UnpackExcelAddress(int rowIndex, int columnIndex, ParsingContext parsingContext, ParsingScope scope, ILexer lexer, Dictionary<string, string> variables)
{
var formula = parsingContext.ExcelDataProvider.GetRangeFormula(_worksheet.Name, rowIndex, columnIndex);
if (string.IsNullOrWhiteSpace(formula))
{
// When excel address doesn't contain information about any excel formula, we should just use external input data parameter provider.
return $"p[{rowIndex},{columnIndex}]";
}
// When formula is provided, try to identify that variable is not defined yet
// TODO Worksheet name is not included in variable name, potentially that can cause conflicts
// Extracting and reusing calculations via local variables improves performance for 0.0045ms
var cellVariableId = $"C{rowIndex}R{columnIndex}";
if (variables.ContainsKey(cellVariableId))
{
return cellVariableId;
}
// When variable does not exist, transform new formula and register that to variable scope
variables.Add(cellVariableId, TransformToSharpCode(formula, parsingContext, scope, lexer, variables));
return cellVariableId;
}
Остаётся только обернуть полученный преобразованный код в статическую функцию, прилинковать сборку с функциями совместимости и провести компиляцию динамической сборки. Загрузить её в память, получить ссылку на нашу функцию — и можно использовать.
Пишем класс-обёртку для тестирования и запускаем тесты с замером времени.
public void SetUp()
{
// Initialize excel package by EPPlus library
_package = new ExcelPackage(new FileInfo(_fileName));
_workbook = _package.Workbook;
_worksheet = _workbook.Worksheets[1];
_inputRange = new ExcelRange[10];
for (int rowIndex = 0; rowIndex < 10; rowIndex++)
{
_inputRange[rowIndex] = _worksheet.Cells[rowIndex + 1, 2];
}
// Access to result cell and extract formula string
_resultRange = _worksheet.Cells[11, 2];
var formula = _resultRange.Formula;
// Initialize parsing context and setup data provider
var parsingContext = ParsingContext.Create();
parsingContext.ExcelDataProvider = new EpplusExcelDataProvider(_package);
// Transform Excel formula to CSharp code
var sourceCode = TransformToSharpCode(formula, parsingContext);
// Compile CSharp code to IL dynamic assembly via helper wrappers
_code = CodeGenerator.CreateCode<double>(
sourceCode,
new string[]
{
// List of used namespaces
"System", // Required for Math functions
"ExcelCalculations.PerformanceTests" // Required for Excel function wrappers stored at ExcelCompiledFunctions static class
},
new string[]
{
// Add reference to current compiled assembly, that is required to use Excel function wrappers located at ExcelCompiledFunctions static class
"....\\bin\\Debug\\ExcelCalculations.PerformanceTests.exe"
},
// Notify that this source code should use parameter;
// Use abstract p parameter - interface for values accessing.
new CodeParameter("p", typeof(IExcelValueProvider))
);
}
В итоге мы имеем прототип данного решения и помечаем её как EPPlusCompiled, Mark-I. После запуска тестов получаем долгожданный результат. Ускорение почти в 300 раз. Уже неплохо, но полученный код всё ещё медленнее нативного в 16 раз. Можно ли лучше?
Да, можно! Попробуем улучшить результат за счёт того, что все ссылки на дополнительные ячейки с формулами мы будем заменять на переменные. В нашем тесте используется многократное использование зависимых ячеек в формуле, поэтому в первой версии транслятора мы получали многократные вычисления одних и тех же данных. Поэтому было принято решение по использованию промежуточных переменных в расчётах. После расширения кода с использованием генерации зависимых переменных мы получили прирост производительности ещё в 2 раза. Данное улучшение носит название EPPlusCompiled, Mark-II. Сравнительная таблица представлена ниже:
| Библиотека | Ср. время (мс) | Коэф. замедления |
| Native | 0,00004 | 1 |
| EPPlusCompiled, Mark-II | 0,003 | 8 |
| EPPlusCompiled, Mark-I | 0,0061 | 16 |
| EPPlus | 1,2089 | 3023 |
При данных условиях и ограничениях времени, которое было выделено на задачу мы получили результат, приближающий нас к производительности нативного кода с небольшим отставанием — в 8 раз, по сравнению с первоначальным вариантом — отставание на несколько порядков, 3028 раз. Но возможно ли улучшить результат и максимально приблизиться к нативному коду, если убрать ограничения по времени и насколько это будет целесообразно?
Мой ответ — да, но времени на реализацию данных техник, к сожалению, у меня уже не оставалось. Возможно, я посвящу данной теме отдельную статью. В данный момент я могу лишь рассказать об основных идеях и вариантах, записав их в виде кратких тезисов, которые были проверены путем обратного преобразования. Под обратным преобразованием я подразумеваю ухудшение нативного кода, написанного вручную, в сторону сгенерированного кода. Данный подход позволяет проверить некоторые тезисы достаточно быстро и не требует значительных изменений в коде. Он также позволяет ответить на вопрос, как ухудшится производительность нативного кода при определённых условиях, что будет означать, что при улучшении сгенерированного кода в автоматическом режиме в обратном направлении мы сможем получить улучшение производительности с похожим коэффициентом.
Тезисы
- Использование двумерного массива, прямой ссылки на функцию преобразования или прямой ссылки на необходимые ячейки данных в памяти не привнесли серьёзных отклонений во времени вычислений;
- Замена обёртки функции для констант на константу или применение агрессивной политики inline для метода дают незначительный рост производительности;
- Замена лямбда-выражений на собственные реализации методов Sum, Max, Min дают небольшой прирост;
- Замена функции Sum на inline-версию даёт значительный рост производительности;
- Оптимизация дерева вычислений (вынесение одинаковых расчётов в отдельную переменную для расчёта данных единожды) даёт значительное улучшение производительности.
Выводы
| Показатель | Native | EPPlus Compiled, Mark-II |
EPPlus 4 EPPlus 5 |
NPOI | Spire | Excel Interop |
| Время инициализации (мс) | 0 | 239 | 241 | 368 | 722 | 1640 |
| Ср. время на 1 проход (мс) | 0,0004 | 0,003 | 0,9174 | 1,8996 | 7,7647 | 50,7194 |
| Ср.кв. отклонение | 0,035884 | 0,0 | 0,0 | 0,0 | 0,0 | n/a |
| Точность | 98,79% | 100,0% | 100,0% | 100,0% | 100,0% | n/a |
| Ошибки | 0,0% | 0,0% | 0,3% | 0,3% | 0,28% | 0,3% |
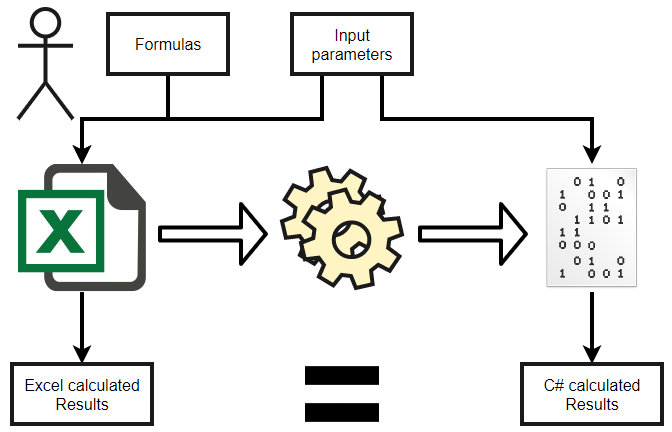
Подводя итоги пройденных этапов, мы имеем механизм преобразования формул напрямую из пользовательского Excel-документа в рабочий код на сервере. Это позволяет использовать невероятную гибкость интеграции Excel с любыми бизнес-решениями без потери мощного пользовательского интерфейса, с которым уже привыкли работать большое число пользователей. Можно ли было разработать столь удобный интерфейс с таким же набором инструментов для анализа и визуализации данных как в Excel за столь короткий период разработки?
А какие самые необычные и интересные интеграции с Excel-документами приходилось реализовывать вам?