Клиент
Наш заказчик — поставщик платформы для проведения онлайн-опросов, которой пользуются тысячи клиентов, в основном в европейских странах. Платформа позволяет проводить не только стандартные опросы, но и кейс-менеджмент, оценку методом 360° и электронное тестирование. Для каждого типа опросов разработан инструмент онлайн-аналитики, представляющий полученные данные в удобном формате.
Задачи
Каждый день авторы создают на платформе новые опросы и рассылают их огромному числу респондентов. Когда множество пользователей одновременно открывают ссылки и отвечают на вопросы, платформа испытывает высокую нагрузку. Чтобы обеспечить масштабируемость, заказчику нужно было определить возможные «узкие места» и устранить возникающие проблемы.
Решение
Каждый опрос поддерживается приблизительно 50 базами данных. При желании опрос можно разделить на несколько страниц, однако получить от конкретный базы только определённую порцию данных нельзя. Соответственно, нужна цельная модель опроса для поддержки логических правил, рандомизации вопросов, валидации и т.п.
Значительная часть таблиц данных — это настройки опросов, различные режимы просмотра и конфигурации логики. Они задаются на стадии создания опроса и крайне редко редактируются потом. Приняв во внимание этот факт, мы решили выделить такие таблицы в отдельный домен и поместить их в отдельное хранилище Memcached. Это решило проблему множественных SQL-запросов от каждого получателя.
Также мы добавили дополнительный этап, на котором модель опроса полностью кэшируется, а затем выгружается из кэша и правильным образом инвалидируется. Поскольку кодовая база была уже готова и в ней было прописано множество функций, мы просто выделили соответствующие интерфейсы и сделали две имплементации: для NHibernate и для т.н. модели представления Cached. Такой подход гарантирует их взаимозаменяемость.
С точки зрения фонового кэширования, логика процесса выглядит следующим образом:
- Система ищет опрос в кэше.
- Если опрос найден, выполняется его валидация. Для этого «дата последнего изменения» сравнивается с «датой в кэше».
- Если опрос признается действительным, система переходит к следующему этапу.
- Если опрос устарел, система повторно кэширует его, а затем использует для текущего запроса.
Поскольку принцип работы кэшированного опроса не отличается от опроса с обычным обращением к базе данных, система легко переключается между этими двумя режимами посредством изменения конфигурации. Это позволяет при необходимости в любой момент вернуться к прямому обращению к базе данных.
Результат
Предложенный подход значительно уменьшил время отклика для каждого респондента. Благодаря кэшированию сократился объем SQL-запросов и улучшилось общее состояние системы, особенно на уровне БД. Полученный уровень масштабируемости позволяет легко и незаметно для пользователя справляться с пиковой нагрузкой.
На графике ниже представлены данные по среднему времени загрузки страницы (в секундах) за неделю:
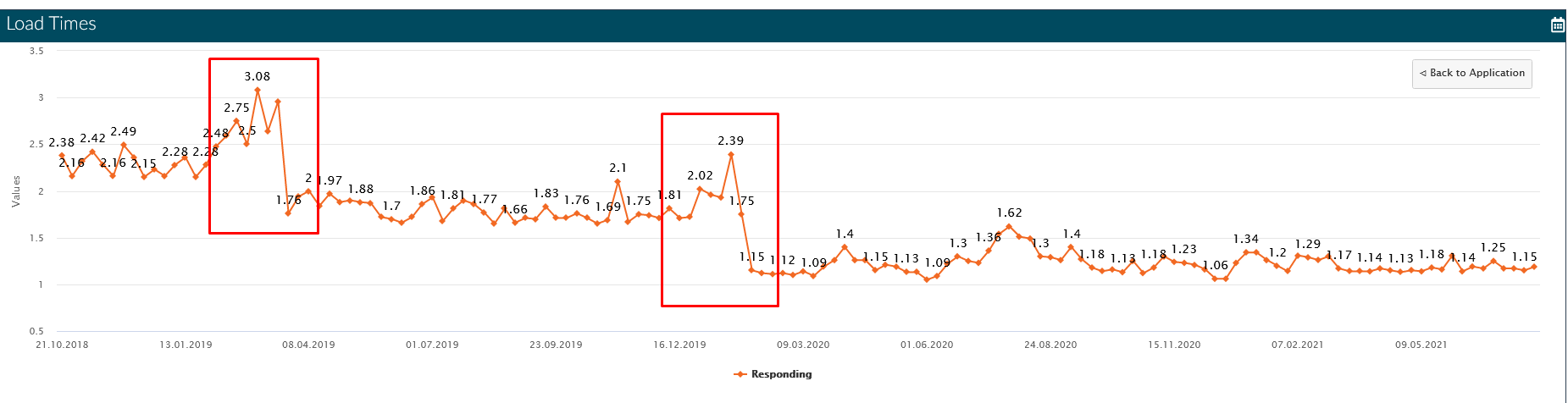
Первое применение кэширования, состоявшееся весной 2019 года, снизило среднее время загрузки страницы с 2,4 с до 1,8 с, т.е. на 25%. В начале 2020 мы сделали ещё одно обновление, устранив некоторые ошибки, и среднее время сократилось еще на 30% — с 1,8 с до 1,2 с. Таким образом, общий результат составил около 50%.